Photo by Headway on Unsplash.
Using Code Interpreter to Analyze US Census Data: The Good, the Impressive & the Ugly
Let’s kick the tires of ChatGPT’s Code Interpreter using the latest US Census’ American Community Survey data. I’ll share my favorite prompt, what impressed me most, and what Code Interpreter got flat wrong.
tl;dr
- The Good: Code Interpreter can open data files and make pretty darn good guesses about what’s inside.
- The Impressive: It can also produce simple weighted scoring models and adjust the weights.
- The Ugly: But sometimes, it produces obviously wrong calculations.
My favorite prompt:
What’s Code Interpreter?
Code Interpreter is a (terribly named) beta feature of ChatGPT that lets you load data files and analyze the data.
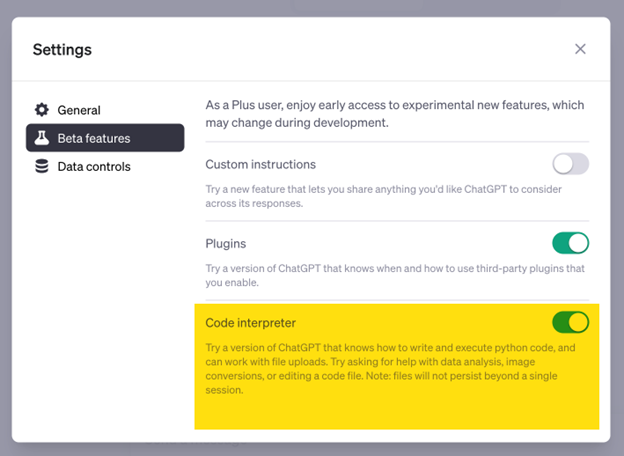
If you want to follow along with me, you need a $20-a-month ChatGPT account. Then you need to turn on Code Interpreter under your Account and then in Settings and Beta.
Once Code Interpreter is on, you can upload data files using the + button.
The Good – Code Interpreter makes good guesses of what’s in a file.
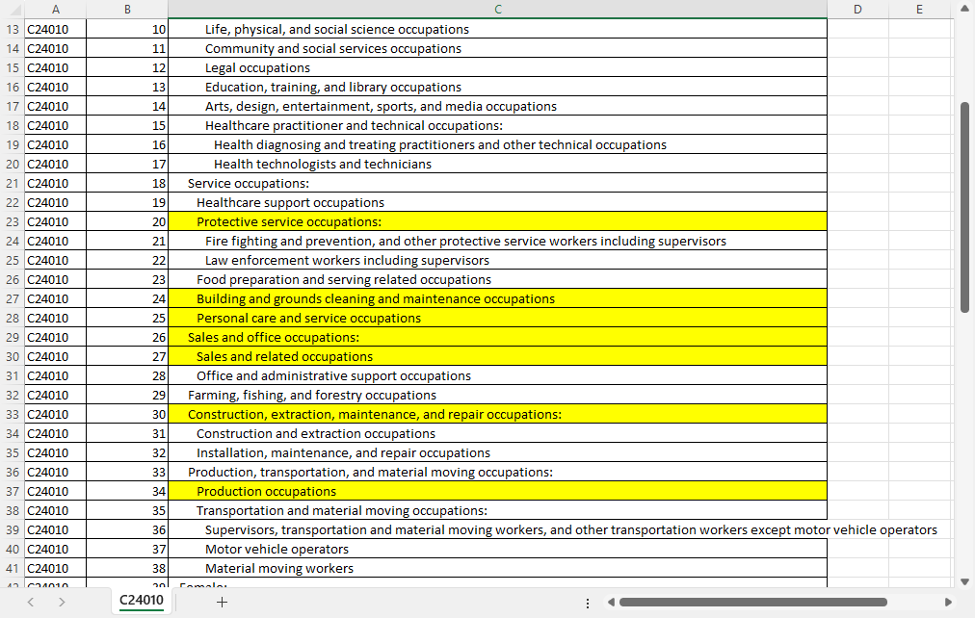
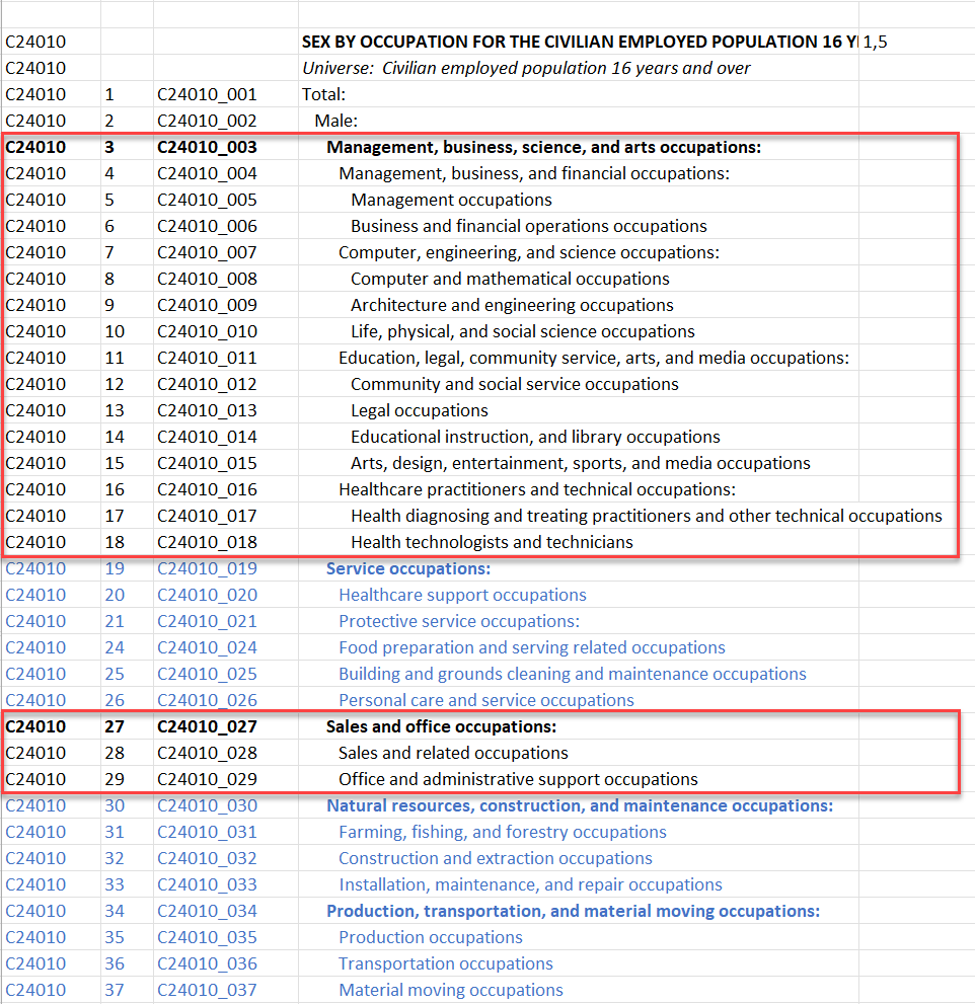
I accidentally uploaded the entire zip file for our DemographicsByCitiesForTexas which has both a data file and a notes and citations file. Code Interpreter effortlessly unzipped the file and identified the data file versus the citations & notes file. It also cut off the human-readable headers and started working with the machine-readable headers – without me having to tell it to.
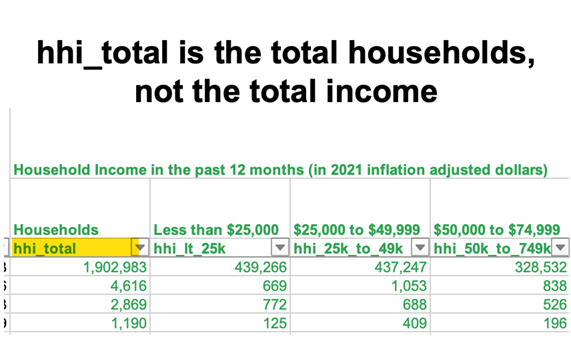
Furthermore, Code Interpreter successfully described what key columns were included in the file.
That said, it’s not all sparkles and unicorns. In the above example, Code Interpreter says that hhi_total is the total number of households. And this is correct. But when I was working with a different dataset, Code Interpreter said that hhi_total was the total household income – which is incorrect.
Lessons Learned
- You can load data files that you aren’t familiar with into Code Interpreter and see if it can make heads or tails of them.
- I may need to update the database headers in Cubit’s files to make it easier for AI tools to “understand” the fields.
- Don’t assume that Code Interpreter will always “understand” the data fields even if it correctly “understood” the fields in a previous analysis.
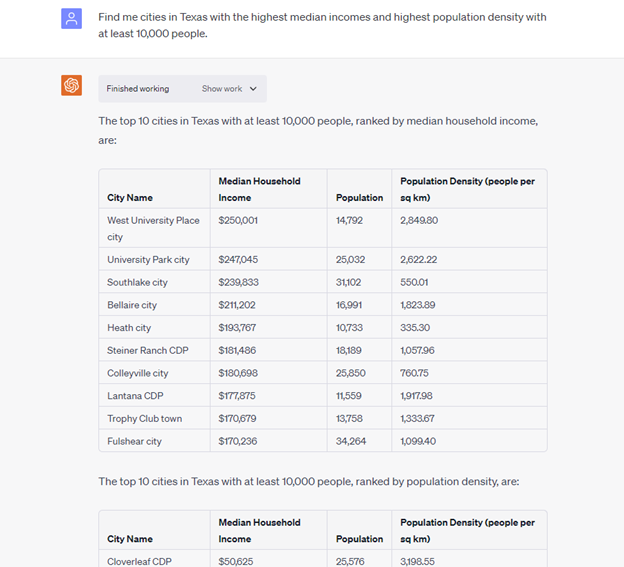
Identifying the Highest Income Cities in Texas
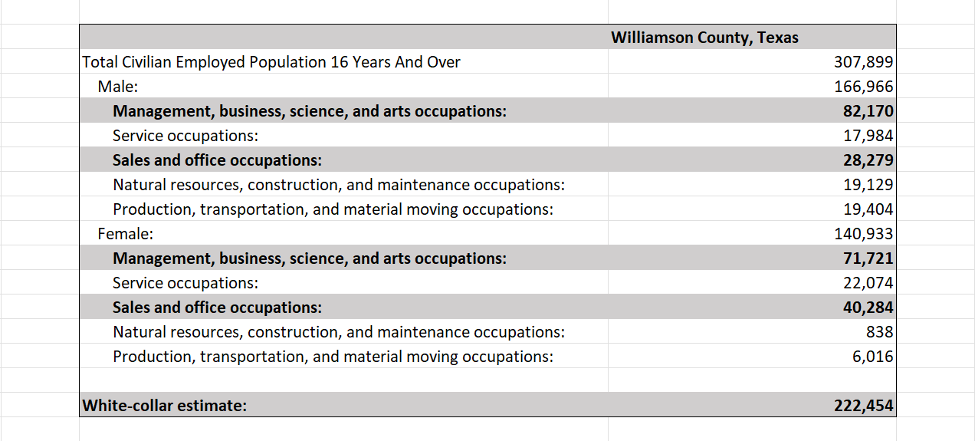
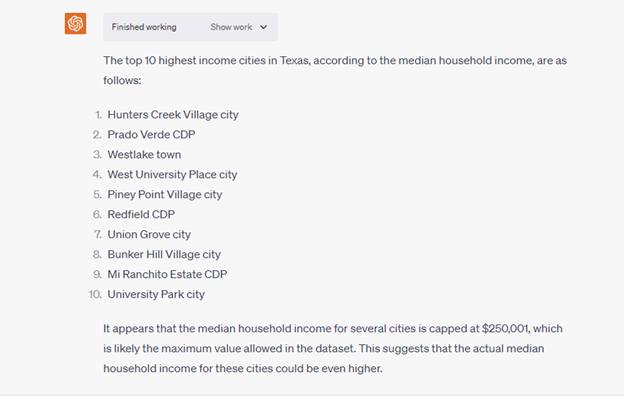
Now let’s dig in! Can Code Interpreter can figure out the highest income cities in Texas using the most recent American Community Survey Census data? Yes, it produced a top ten list of cities based on the correct median household income column in the file. It even called out that the median income doesn’t go higher than $250,001.
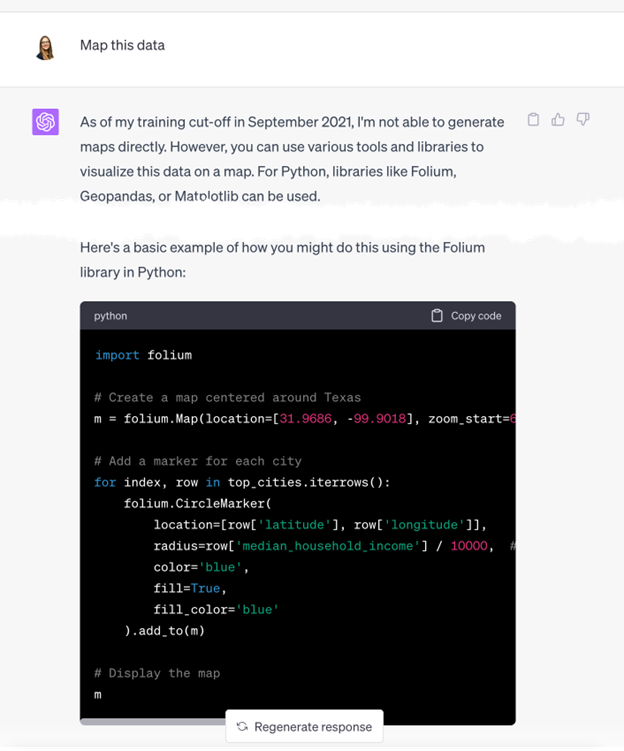
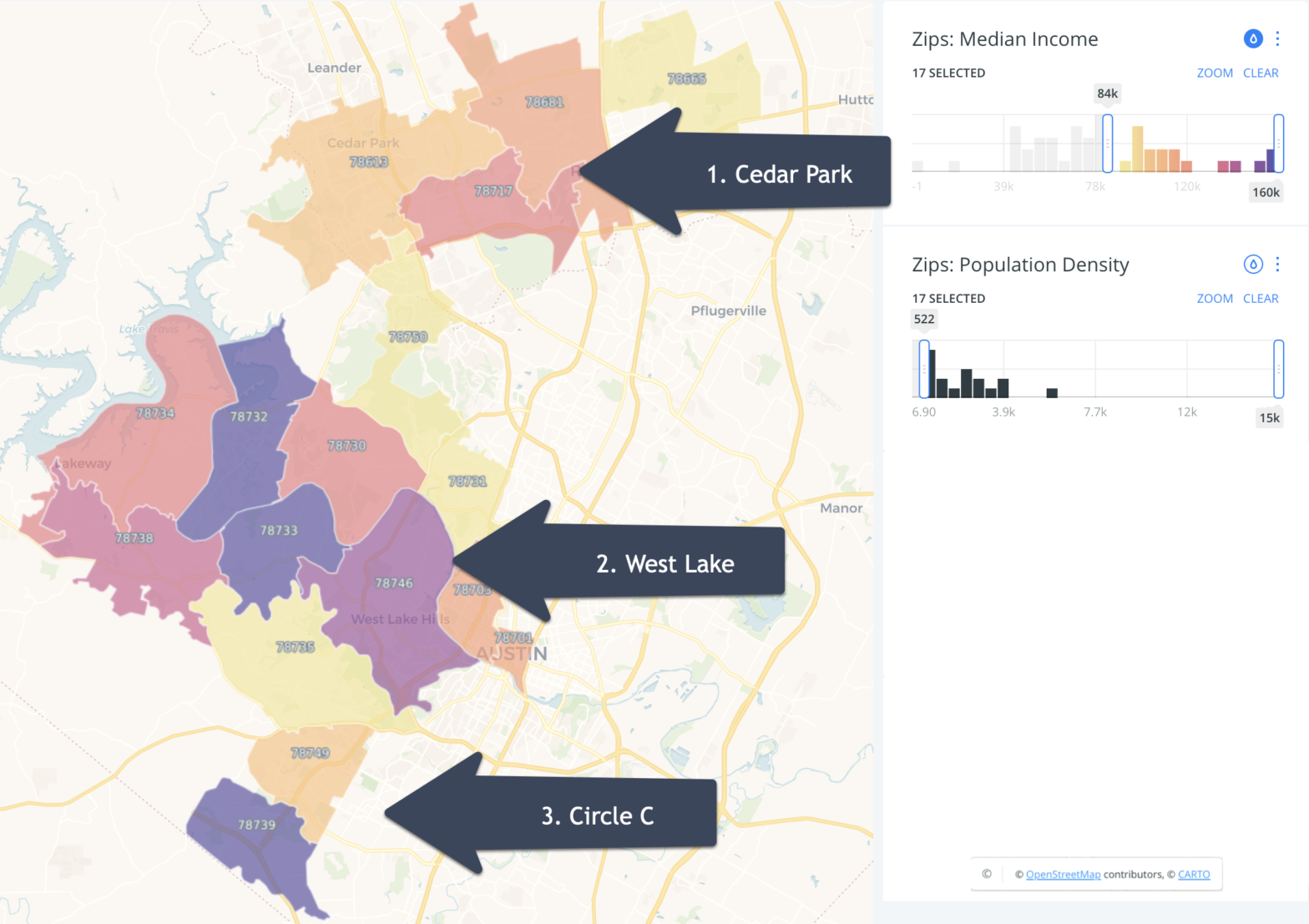
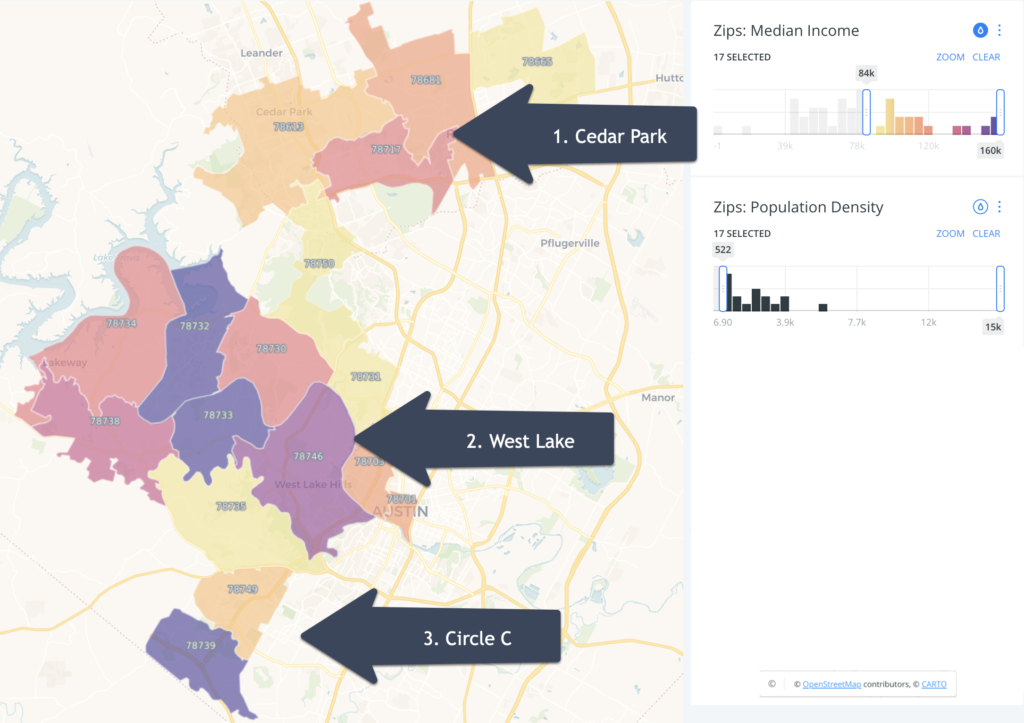
But I’m not impressed yet as I can do the same thing with a simple sort in Excel. So now I want to see something that I can’t do out of the box in Excel, and that’s build a map of these high-income cities so I can see where they are clustered in Texas.
Visualizing the High-Income Cities on a Map
But Code Interpreter can’t build maps directly.
It did, however, suggest some tools to help visualize this data such as Python libraries – which doesn’t help me as I don’t know Python or Folium. Also, Code Interpreter clarifies that it needs coordinates for map building.
Lessons Learned
- Code Interpreter can’t produce maps – bummer! But it can write code for other technologies to produce maps.
- I need to think if we should add latitude/longitude data to our data files.
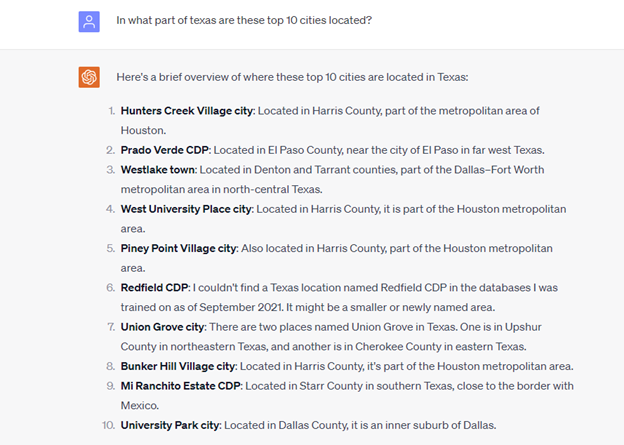
Locating the Top 10 Cities in Texas
So I still want to know where these high-income cities are in Texas. Can Code Interpreter help me do this without a map?
Code Interpreter uses its own data to locate each city and ignores the county data in the file that I provided. But this is only problematic for “Redfield CDP” as it doesn’t have data for this geography where as the file that I provided does.
Could a different prompt give us what we need? Maybe.
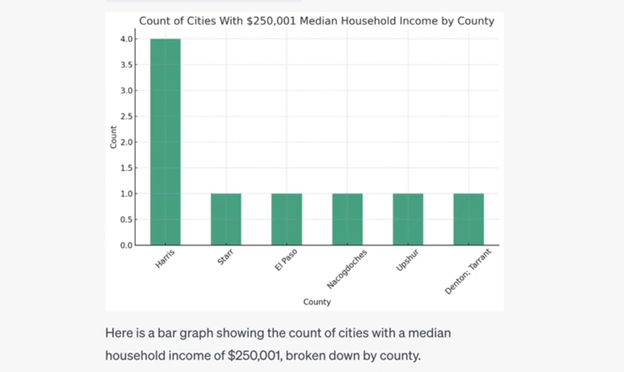
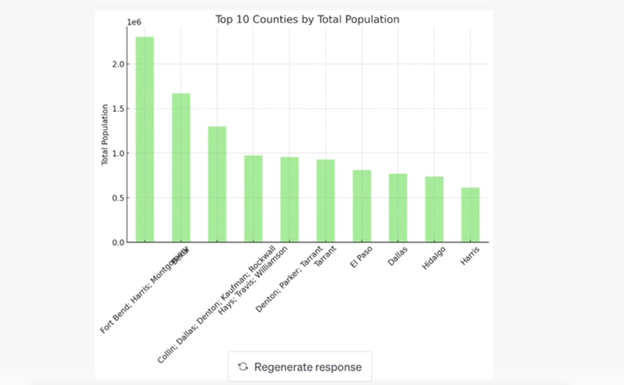
I asked Code Interpreter to provide a graph of the counts of cities with the max median income by county, and it provided a description of the graph and what data was considered. Tada! Ok, I now roughly know where these high income cities in Texas are located.
Show Me Something I Don’t Know.
I’m done exploring high-income cities in Texas, and I’m ready to be impressed. And what could be more impressive than Code Interpreter figuring out something about this dataset that I don’t already know? Here’s the prompt I use.
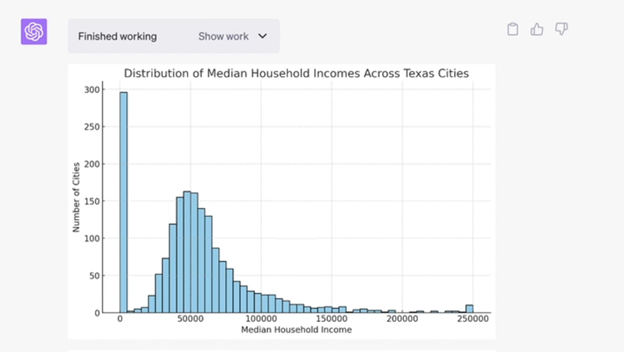
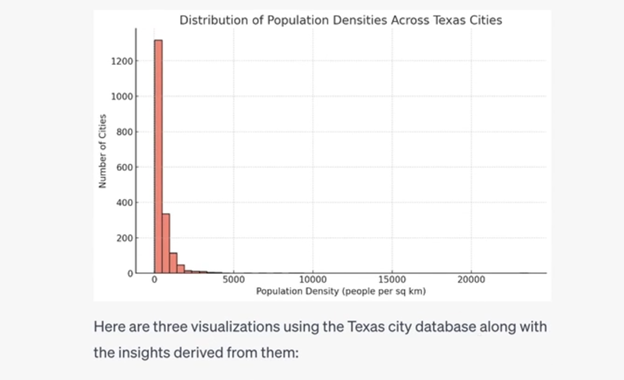
But the results were not as impressive as I hoped and included a distribution of Median Household income across the Texas cities, the top 10 counties by total population (even though the total populations in the file are only for cities?) and the distribution of population densities across the cities. Honestly, I’m underwhelmed.
I’m going to skip a bunch of stuff that didn’t work to get you straight into the good stuff.
The Impressive: Weighted Scoring Model
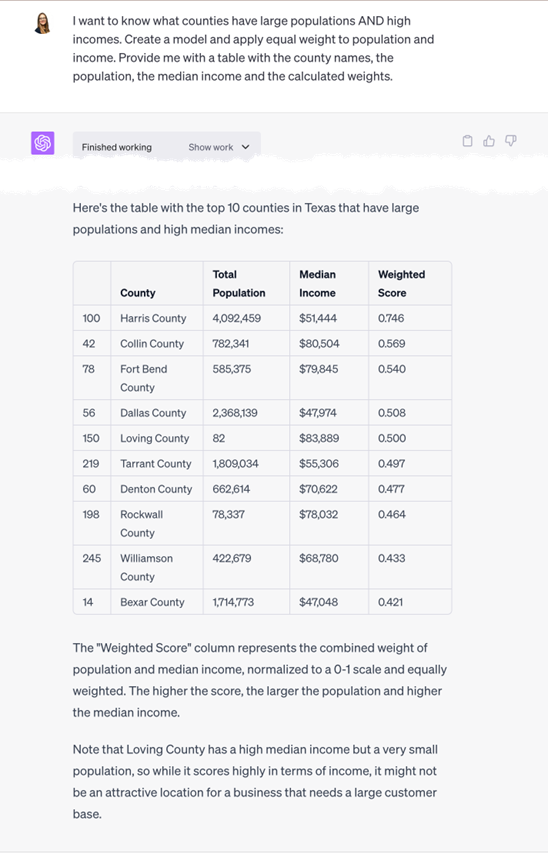
Sometimes, I need to identify geographies that have large populations AND large income AND {insert other variable here}. Let’s see if Code Interpreter can do this.
And it completely fails. I tried a bunch of different prompts and they all failed.
But…
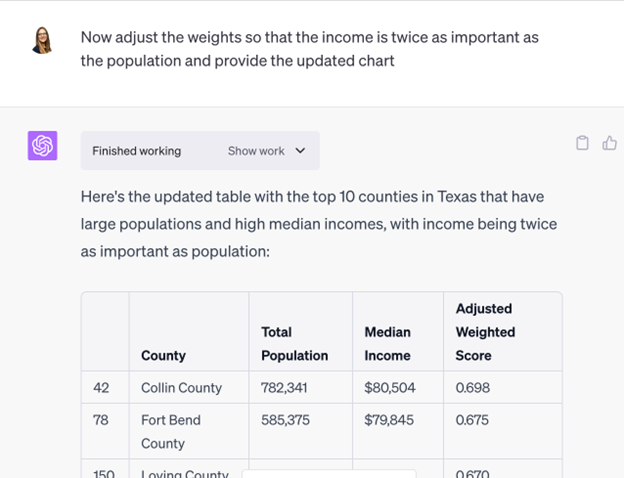
I was explaining what I was trying to do to Sara of FromThePage, and she asked me how I’d solve this problem without Code Interpreter. I told her that I’d build a simple model and apply weights. And she brilliantly asked, “I wonder what Code Interpreter would do if you told it that?” Good point! So I did but this time using our Texas county dataset.
And that’s just what I wanted – a simple weighted model. But I don’t want Harris County to ALWAYS be at the top with its outlier population of 4 million people. So let’s see if Code Interpreter will tweak the weights.
This simple weighted model was the most interesting thing that I got Code Interpreter to do. I’ve been playing around with projections and change over time data, and I’m hopeful that I’ll get something even more impressive soon.
Lesson Learned
- Code Interpreter can’t solve data problems for you – beyond simple sorts and graphs. To get it to do something impressive, you must already know the solution to your problem AND you must figure out exactly how to tell it to produce what you want. Alternatively, I could need more practice at prompt writing.
The Ugly: Obvious Calculation Errors
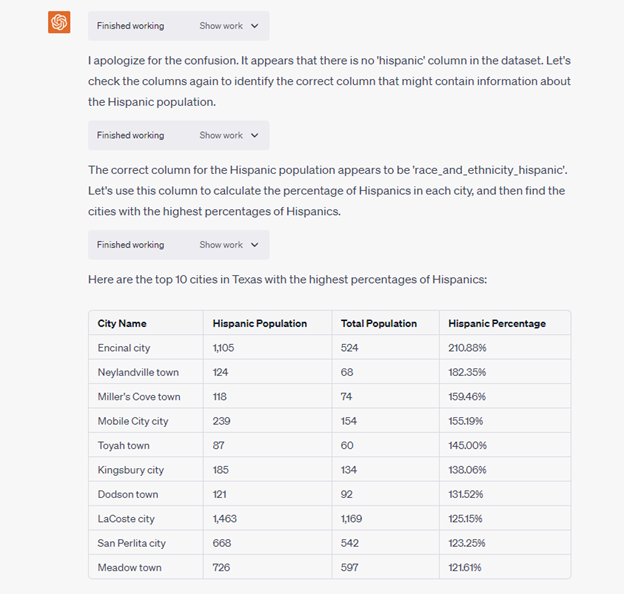
I was on the phone with a client who wanted to identify zips where many Hispanics live. And since I had already loaded demographics for Texas cities into Code Interpreter, I thought I’d see how well it would do.
First off, Code Interpreter had problems locating a “hispanic” column in the dataset when there’s a clearly named column: “race_and_ethnicity_hispanic”. It thinks it fixes the problem but ends up using the wrong universe which results in Hispanic percentages over 100% — which is impossible.
So this is dumb, but to be fair, Code Interpreter points out the error.
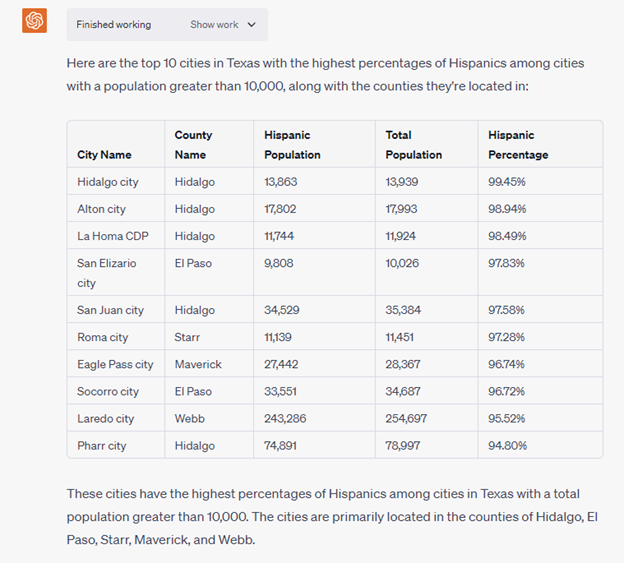
I tried to get Code Interpreter to fix the problem on its own, but it couldn’t.
When I pointed Code Interpreter to the right columns to use, then it corrected the calculation. But if I’m going to have to spell out columns, then I’ll probably just stick with a database or Tableau or {insert other data tool that I know better}.
Lessons Learned
- Double-check all Code Interpreter calculations.
- When you start getting results that are obviously wrong, reload the file and start over rather than trying to get Code Interpreter to find and fix the error.
And One Bonus Lesson Learned that Doesn’t Fit Anywhere Else
- You could use Code Interpreter like a flow in Tableau Prep. You drop in standardized data, run a series of prompts, and get a standardized output in text or data visualizations.
Conclusion
I’ve never incorporated a tool into my daily workflow as quickly as I have ChatGPT. Every day, I use it to do something a little different – be it writing email subject lines or rewriting this wordy blog post, or producing formulas for Google Sheets that all I need to do is to copy and paste and they work (mostly).
As you can see from the above post, I’m still a novice in terms of using Code Interpreter to analyze Census data. In fact, my favorite use cases for Code Interpreter aren’t when I’ve asked it to analyze Census data, but when I’ve asked it to analyze data for my business, Cubit.
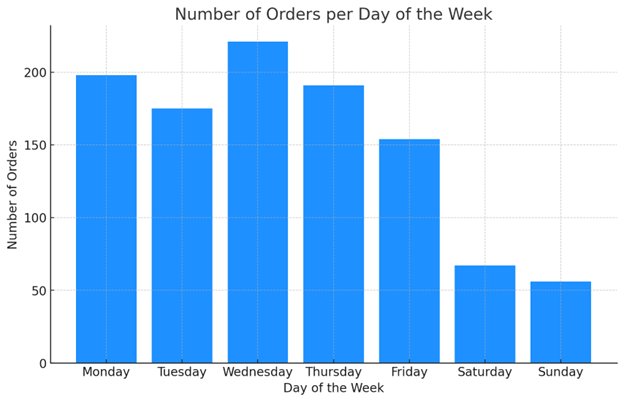
For example, I wanted to know what days of the week were most popular for making purchases of one of our products. I was able to load product data into Code Interpreter, and it spit out the graph slightly faster than I could have built the same thing in Excel. But I didn’t have the spend my time fixing date format issues – Code Interpreter did this for me.
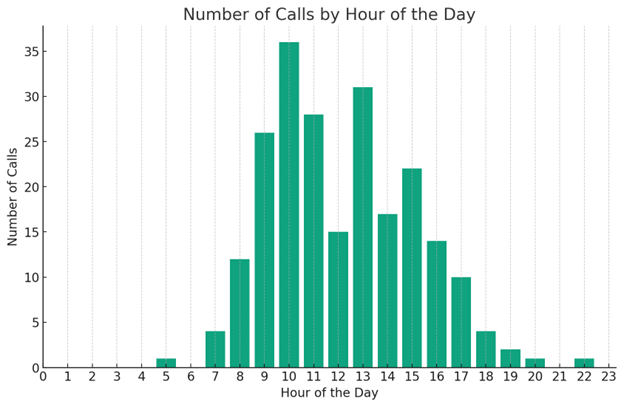
Also, I wanted to know what hours of the day I receive the most phone calls. Code Interpreter was able to clean up different time formats and produce the following graph – again slightly faster than I could have done AND saving me the brainpower from having to fix data format issues.
So my final lessons learned are:
- Code Interpreter is fun to use with internal business data as makes simple graphs that I can use to answer simple questions.
- I need to keep using Code Interpreter daily with Census data or internal data to improve my prompt writing and learn what it can and can’t do.
Wow! You’ve read to the end. Color me impressed. You, my friend, are EXACTLY the type of person that I want to hear from, and here’s where you can send me a message.